






Alongside the recent growth in digital treatments for mental health, there has been a rise in the exploration of how machine learning (ML) can be used in this field. Much of the research so far is focused on the efficacy and accuracy of machine learning models, with little research into how these models will work in real-world applications. (Reference)
At SilverCloud, we have developed an outcome prediction tool based on machine learning models. By using machine learning models to predict outcomes, we can determine at an early stage whether a patient is likely to improve, or not, creating the opportunity for supporters (the person/clinician guiding the user through the digital intervention), to adapt their approach to ensure treatment success.
Machine learning supported outcome prediction
The outcome prediction tool that was developed is based on a fully anonymized analysis of over 46,000 previous users of SilverCloud’s Space from Depression and Anxiety program. Two ML models were trained to learn the trajectories of user outcome scores on two common measures of depression and anxiety, the Patient Health Questionnaire-9 (PHQ-9) and Generalised Anxiety Disorder-7 (GAD-7) respectively. The models predict whether a client is likely to achieve a reliable improvement in their symptoms by the end of treatment, and they do this with above 87% accuracy after 3 reports of clinical symptom (~3 weeks into treatment). Reliable improvement is defined as a drop of at least 6 points in a PHQ-9 score or 4 points in a GAD-7 score, from the baseline. These relatively large changes in scores ensure that the improvement exceeds the measurement error in the scales, thus reflecting a highly significant clinical improvement of symptoms of depression or anxiety.
Outcome prediction in context
Users of SilverCloud work through their program content with the help of a trained supporter, who provides weekly or bi-weekly reviews through the platform. To review a user’s progress, supporters can see what a user has done on the platform in the previous week, along with any messages the user might have sent and their answers to clinical questionnaires, like the PHQ-9 and GAD-7. Early user research suggests that displaying outcome prediction results to trained supporters could help them, at an earlier stage, to identify those users who are not progressing as expected and may be at risk of poor outcomes. Such information could enable supporters to change their approach as necessary, for example recommending a tailored piece of content or a more supportive message, and thereby increase the likelihood of a patient improving.
Designing an interface for machine learning
Aside from the development of the two prediction models, the research also sought to better understand how the design of a User Interface (UI) for the model integration shaped how supporters would understand, interpret, and effectively action model outputs within their workflows. To address this challenge, a set of design mock-ups were developed to be reviewed with supporters. The aim of these design review sessions was to understand how the outcome prediction results could fit into their workflow, which types of designs and characteristics were most comprehensive, and what level of contextual information was needed to aid in the understanding of the model outputs. One of the key design challenges was creating a UI that would allow supporters with only a basic knowledge of machine learning to gain sufficient understanding and the ability to appropriately interpret the outputs of the prediction.
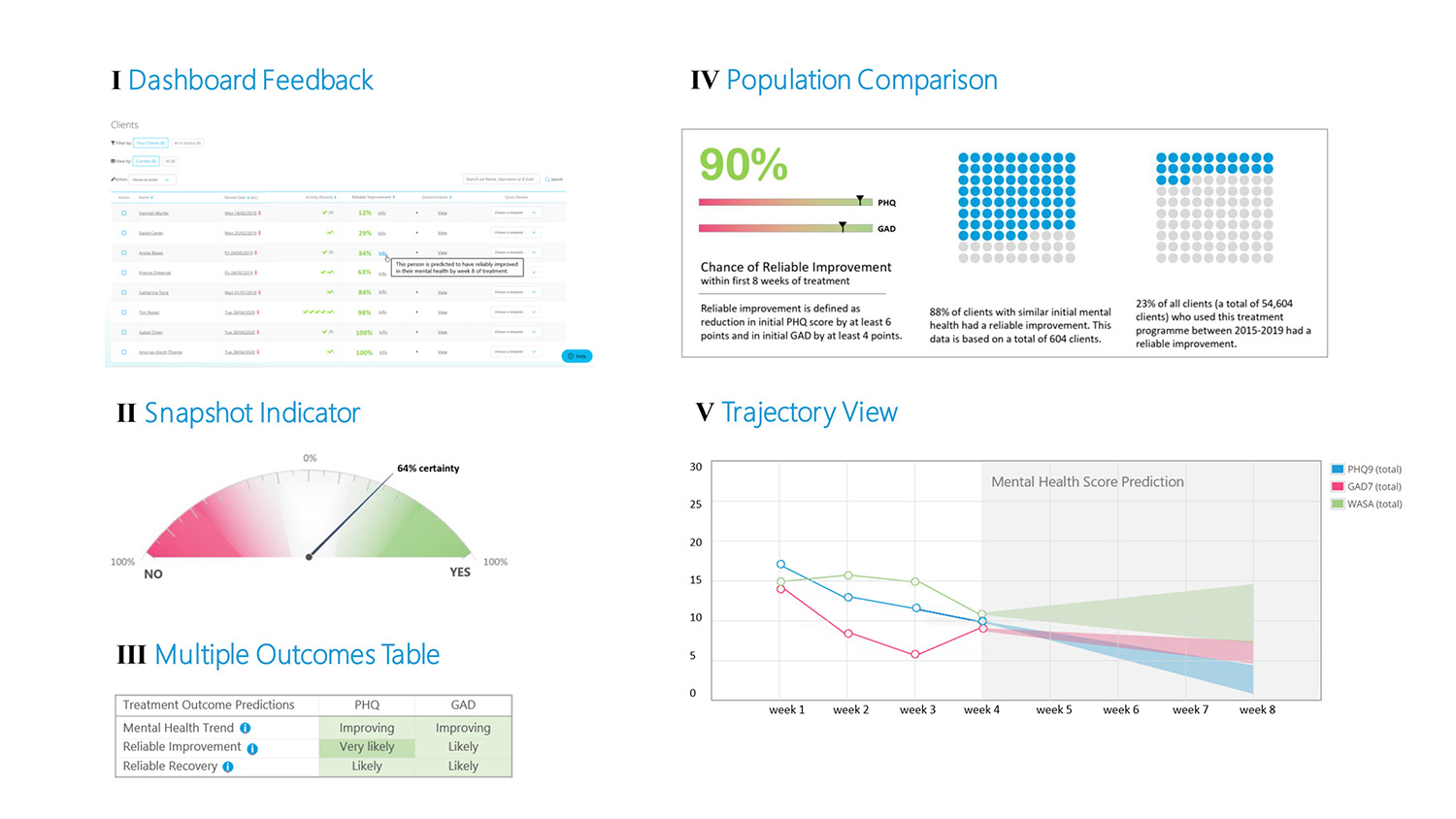
The initial design concepts were intentionally quite different from each other, with the aim of representing several different ways of understanding data, such as visually, textually, numerically, etc. We also wanted to understand how the use of colour affected the interpretation. These sessions resulted in a design that used a combination of data representations, to accommodate different preferences for reading data.
One of the crucial elements in creating a successful design was getting the right balance of information. We wanted it to be understood quickly, so as not to take up too much time in a supporter’s workflow. The visual indicator alongside the label is intended to allow supporters to understand the predictions at a glance. More information is available in the info button if needed, but it doesn’t clutter the interface. Several rounds of iteration on the text were required to ensure it would give an accurate indication of the prediction and reduce the risks of misinterpretation.
Pilot
Once the UI was developed, researchers at SilverCloud conducted a pilot study with 6 supporters in the US. The aim of this study was to understand how the supporters incorporated the tool into their work, as well as the understandability and acceptability of the prediction outputs. The tool was made available to the supporters for a period of 8 weeks and interviews were conducted with each supporter every second week. A focus group concluded the 8-week period. Overall feedback on the tool was positive, with all the supporters indicating they would like to continue to use the tool. There was also a high level of trust in the accuracy of the tool.
Design Iteration
Certain use cases caused issues in interpretation, for example clients who initially scored low on the PHQ-9 or GAD-7 might receive a negative prediction, as the threshold for reliable improvement is a drop of 6 points. However, as these clients have low scores and minimal symptoms to begin with, they are already doing well and have less or no scope for achieving significant enough improvements. Use cases such as this led to restrictions in tool use, so that it would only show predictions for clients who can achieve reliable improvement.
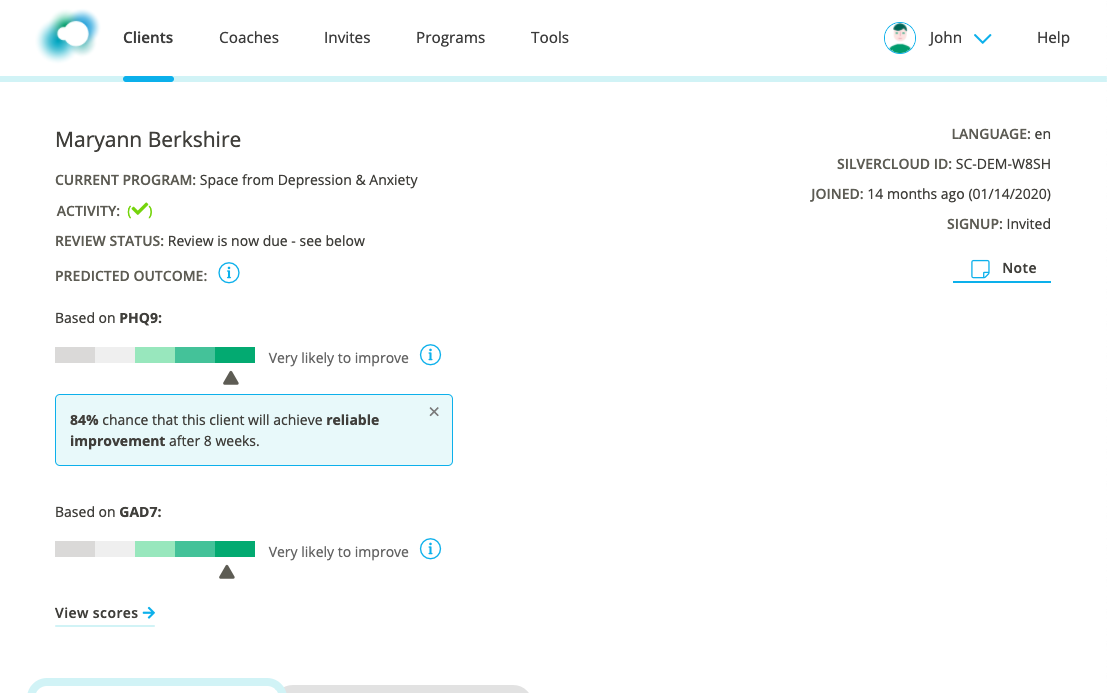
We also learned the importance of explicit language in helping users to interpret the prediction tool correctly. We changed the label text from “Likely to improve” to “Likely to achieve reliable improvement” and the title of the tool from “Predicted Outcome” to “Prediction of Reliable Improvement”. We added variations on the empty state explanation, so rather than just saying no prediction available, the UI indicates whether this is because it’s too early, or not applicable to the user (as in the use case above, where the client starts below the threshold).
Another aspect that proved to be important in the interpretation was the context of the scores that went into creating the prediction. To address this we added a quick view reminder of the latest score, and a link to see the full set of scores.
The pilot also helped us to revise the training that supporters would need prior to using the prediction tool. We were able to test whether the concepts were understood, and revise the training documents and case studies accordingly. We realised the importance of this training in ensuring the context of Machine Learning information is properly understood, for example ensuring there isn’t an over-reliance as the model can sometimes be wrong.
Further Research
Following on from the pilot study, SilverCloud is conducting a Randomized Control Trial to test the acceptability and clinical use of the tool with supporters at Berkshire NHS Trust in the UK. This trial will be the first to systematically study the use of a prediction tool within a digital platform for mental healthcare delivery.
Acknowledgements
Initial user research and the development of the two ML models for predicting reliable improvements in PHQ-9 and GAD-7 outcomes for patients enrolled in SilverCloud’s “Space from depression and anxiety” program, was conducted in collaboration with researchers at Microsoft Research Cambridge, UK.
Reference paper:

